TU Wien:Algorithmen und Datenstrukturen VU (Szeider)/Übungen 2019S
Übung 1[Bearbeiten | Quelltext bearbeiten]
Aufgabe 1.1[Bearbeiten | Quelltext bearbeiten]
Gegeben ist folgendes Stable Matching Problem.
1. 2. 3. 4. 1. 2. 3. 4. A L M N O L B C A D B L N M O M D A B C C M O L N N A B C D D L O N M O A B D C
Aufgabe 1.2[Bearbeiten | Quelltext bearbeiten]
Gegeben sind die folgenden Funktionen:
Kreuzen Sie in der folgenden Tabelle die zutreffenden Felder an und begründen Sie Ihre Antworten (formaler Beweis ist nicht notwendig):
| f(n) ist in | Θ(.) | O(.) | Ω(.) | keines |
X |
||||
X |
X |
X |
||
X |
Hinweis: Setzen Sie statt dem Punkt die entsprechende Funktion (g1, g2 bzw. g3) ein. Beispielsweise ist die Zelle links oben als "f(n) ist in Θ(g1(n))" zu lesen.
Aufgabe 1.3[Bearbeiten | Quelltext bearbeiten]
Fügen Sie bei den folgenden Aufwandsabschätzungen die entsprechenden Symbole Θ, O oder Ω in die dafür vorgesehenen Kästchen ein:
Ω |
||
Θ |
||
O |
||
O |
||
O |
||
Θ |
||
Θ |
||
Ω |
Ist die Lösung in jedem Fall eindeutig? Begründen Sie ihre Antwort.
Aufgabe 1.4[Bearbeiten | Quelltext bearbeiten]
(a) Beweisen oder widerlegen Sie, dass für die folgende Funktion f(n) die Beziehung gilt:
(b) Beweisen oder widerlegen Sie, dass
gilt.
Hinweis: Bedenken Sie, dass für einen Beweis gegebenenfalls auch geeignete Werte für die Konstanten c1, c2 und n0 angegeben werden müssen.
Aufgabe 1.5[Bearbeiten | Quelltext bearbeiten]
Bestimmen Sie die Laufzeiten der unten angegebenen Algorithmen in Abhängigkeit von n in Θ-Notation. Verwenden Sie hierfür möglichst einfache Terme.
x = 4*n
y = 0
while x > 0
x = ⌊x/2⌋
for i = 1,...,n
y = y + x*i
i = 1
x = 1
while i < n
a = 4*i
for j = a, ..., 1
x = x + j
i = a/2
Aufgabe 1.6[Bearbeiten | Quelltext bearbeiten]
Bestimmen Sie die Laufzeiten und die Werte der Variablen a und b nach der Ausführung der unten angegebenen Algorithmen in Abhängigkeit von n in Θ-Notation. Verwenden Sie hierfür möglichst einfache Terme.
a = 1
b = 1
for c = 1, ... 1/2 log_2 n
a = 4a
b = c
a = ⌊a/2⌋
i = 2^(2b)
while i > 1
i = ⌊i/2⌋
a = n^3
b = 1
while a > 1
b = b + 1
c = n
do
a = ⌊b/2⌋
c = 2c/n
b = b*n
while c >= n
Aufgabe 1.7[Bearbeiten | Quelltext bearbeiten]
Zeigen Sie, dass gilt.
Hinweis: Verwenden Sie die Definitionen aus den Folien.
Übung 2[Bearbeiten | Quelltext bearbeiten]
Aufgabe 2.1[Bearbeiten | Quelltext bearbeiten]
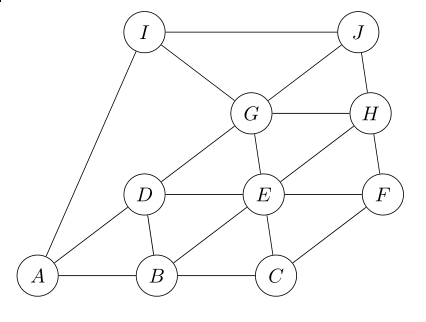
Führen Sie auf dem nachfolgenden Graphen die Breiten- und Tiefensuche entsprechend den Algorithmen in den Vorlesungsfolien durch. Geben Sie dabei jeweils eine gültige Reihenfolge an, in der die Knoten besucht werden.
Zeichnen Sie zusätzlich den Tiefen- und Breitensuchbaum. Eine Kante v → w in diesen Bäumen drückt aus, dass Knoten w von Knoten v aus entdeckt wurde.
Verwenden Sie jeweils A als Startknoten. Haben Sie die Wahl zwischen mehreren Knoten gehen Sie alphabetisch vor.
-%C3%9Cbungen_2019S_-_Task21.png)
Aufgabe 2.2[Bearbeiten | Quelltext bearbeiten]
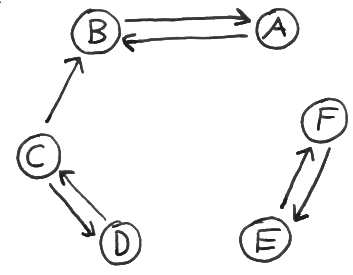
Zeichnen Sie gerichtete Kanten zwischen den gegebenen Knoten ein, so dass der resultierende, gerichtete Graph exakt zwei schwache und drei starke Zusammenhangkomponenten hat. Geben Sie zusätzlich die Komponenten an.
-%C3%9Cbungen_2019S_-_Task22.png)
-%C3%9Cbungen_2019S_-_Task22_solution.png)
starke Zusammenhangkomponenten: (A,B), (C,D), (E,F)
schwache Zusammenhangkomponenten: (A,B,C,D), (E,F)
Aufgabe 2.3[Bearbeiten | Quelltext bearbeiten]
Beantworten Sie folgende Fragen zu Graphen:
(a) Wir nehmen eine kleine Modifikation an dem in der Vorlesung vorgestellten Pseudocode für Tiefensuche (Foliensatz Graphen) vor. Als letzte Zeile der Funktion DFS1 wird (nach der foreach-Schleife) Discovered[u] <- false eingefügt.
Wie oft tritt nun der Fall ein, dass DFS1 keinen weiteren Rekursionsaufruf tätigt, wenn dieser modifizierte Algorithmus (also DFS mit beliebigen Startknoten) auf den vollständigen ungerichteten Graphen (d.h. von jedem Knoten existiert eine Kante zu allen anderen Knoten) mit 15 Knoten ausgeführt wird?
(b) Sei G ein vollständiger gerichteter Graph (d.h. von jedem Knoten existiert eine gerichtete Kante zu allen anderen Knoten) mit 20 Knoten. Wie viele Kanten müssen mindestens entfernt werden, sodass zumindest eine topologische Sortierung existiert?
Aufgabe 2.4[Bearbeiten | Quelltext bearbeiten]
Konstruieren Sie einen schlichten, ungerichteten, zusammenhängenden Graphen mit mehr als sechs Knoten, der mindestens drei Knoten mit Grad drei enthält. Wählen Sie den Graphen so, dass es (für einen von Ihnen gewählten Startknoten) für die Breiten- und Tiefensuche (zumindest) eine identische Abarbeitungsreihenfolge der Knoten gibt.
Aufgabe 2.5[Bearbeiten | Quelltext bearbeiten]
Wir bezeichnen einen ungerichteten Graphen als bipartit, wenn sich dessen Knoten in zwei Mengen und aufteilen lassen, für die gilt: , und .
Finden Sie einen Algorithmus, der in linearer Laufzeit bestimmt, ob ein gegebener Graph bipartit ist. Entwickeln Sie eine Lösung in detailliertem Pseudocode und argumentieren Sie, dass der Algorithmus korrekt ist und die geforderte Laufzeitschranke gilt.
Aufgabe 2.6[Bearbeiten | Quelltext bearbeiten]
Gegeben sind n Programme , welche auf einer Festplatte mit einer Kapazität von D Megabyte gespeichert werden sollen. Der Platz, der für ein Programm benötigt wird, ist s i Megabyte. Nehmen Sie an, dass es nicht möglich ist, alle Programme gleichzeitig auf der Festplatte zu speichern (es gilt also ).
(a) Maximiert ein Greedy-Algorithmus, der die Programme in aufsteigender, nach Größe geordneter, Reihenfolge auswählt, die Anzahl der zu speichernden Program- me? Geben Sie einen Beweis oder ein Gegenbeispiel an.
(b) Maximiert ein Greedy-Algorithmus, der die Programme in absteigender, nach Größe geordneter, Reihenfolge auswählt, die Auslastung der Festplatte? Geben Sie einen Beweis oder ein Gegenbeispiel an.
Aufgabe 2.7[Bearbeiten | Quelltext bearbeiten]
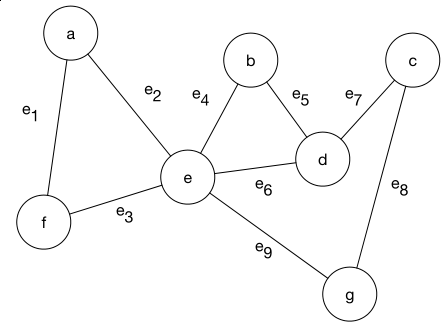
Bestimmen Sie den minimalen Spannbaum für folgenden Graphen. Verwenden Sie dazu den Algorithmus von Prim und beginnen Sie bei Knoten F . Haben Sie danach die Wahl zwischen mehreren Knoten gehen Sie alphabetisch vor. Geben Sie nach jedem Schleifendurchlauf den aktuell ausgewählten Knoten, den Inhalt der Priority Queue Q, die Knotenmenge S und das Gewicht des aktuellen Spannbaums an.
-%C3%9Cbungen_2019S_-_Task27.png)
Übung 3[Bearbeiten | Quelltext bearbeiten]
Aufgabe 3.1[Bearbeiten | Quelltext bearbeiten]
Gegeben ist der folgende Min-Heap:
-%C3%9Cbungen_2019S_-_Task31.png)
(a) Fügen Sie die Elemente 8 und 2 in der angegebenen Reihenfolge in den Min-Heap ein. Stellen Sie nach jedem Einfügevorgang den resultierenden Heap als Baum dar. Erklären Sie dabei, wie Sie Heapify-up korrekt anwenden.
(b) Entnehmen Sie aus dem in Aufgabe 1 gegebenen Min-Heap drei Mal das kleinste Element. Stellen Sie nach jedem Löschvorgang den resultierenden Heap als Baum dar. Erklären Sie dabei, wie Sie Heapify-down korrekt anwenden.
Anmerkung für Interessierte: Mithilfe von Heaps können Arrays sortieren werden. Ein bekannter Sortieralgorithmus, der einen Heap als zentrale Datenstruktur verwendet, ist Heapsort.
Aufgabe 3.2[Bearbeiten | Quelltext bearbeiten]
Gegeben ist das Array [7, 3, 4, 6, 2, 9, 1].
(a) Führen Sie Mergesort auf dem oben gegebenen Array aus und geben Sie Zwischenschritte in Form eines Ablaufdiagrammes wie im Foliensatz Divide-and-Conquer an.
(b) Führen Sie Quicksort auf dem oben gegebenen Array aus. Wählen Sie stets das erste Element als Pivot-Element aus und implementieren Sie den Schritt des Aufteilens so, dass die Elemente einer Subfolge immer in derselben Reihenfolge angeordnet werden wie in der Originalfolge. Geben Sie die Zwischenschritte wie im Foliensatz Divide-and-Conquer an.
Aufgabe 3.3[Bearbeiten | Quelltext bearbeiten]
Ein Vertreter der linearen Sortieralgorithmen ist Radixsort. Die Grundidee basiert darauf, dass die zu sortierenden Wörter oder Zahlen mehrmals in Fächer (Buckets) verteilt werden, sodass nach der letzten Verteilung die Elemente in sortierter Reihenfolge entnommen werden können.
Finden Sie zunächst mithilfe einer Internet- und/oder Literaturrecherche heraus, wie Radixsort genau funktioniert.
(a) Sortieren Sie die folgenden Zahlen aufsteigend mithilfe von Radixsort:
- 447, 415, 683, 437, 613, 645, 435
3 5 7
683 415 447
613 645 437
435
- 683, 613, 415, 645, 435, 447, 437
1 3 4 8 613 435 645 683 415 437 447
- 613, 415, 435, 437, 645, 447, 683
4 6 415 613 435 645 437 683 447
- 415, 435, 437, 447, 613, 645, 683
(b) Handelt es sich bei Radixsort um einen Divide-and-Conquer-Algorithmus? Begründen Sie Ihre Antwort.
Aufgabe 3.4[Bearbeiten | Quelltext bearbeiten]
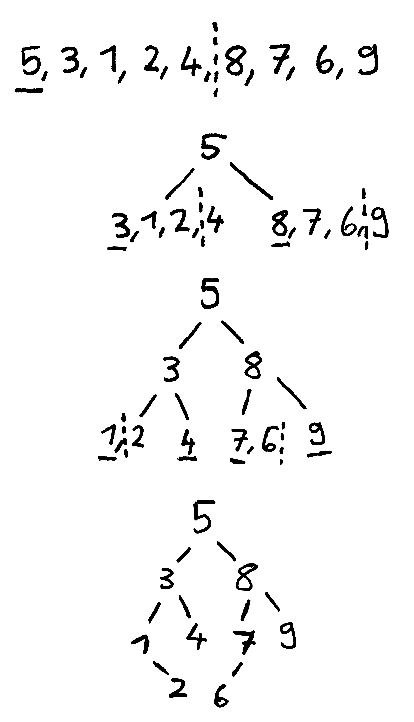
Gegeben ist die preorder-Traversierung eines binären Suchbaumes:
5, 3, 1, 2, 4, 8, 7, 6, 9
Rekonstruieren Sie mithilfe dieser Information den binären Suchbaum nach dem Divide-and-Conquer-Prinzip. Geben Sie dabei jeweils den aktuellen Zustand des Baumes nach jedem Teile-Schritt an.
- Preorder: Wurzel, linker Unterbaum, rechter Unterbaum
- binärer Suchbaum: jeder Knoten im linken Unterbaum muss kleiner und jeder Knoten im rechten Unterbaum muss größer sein als der aktuelle Knoten
-%C3%9Cbungen_2019S_-_Task34_solution.jpg)
Aufgabe 3.5[Bearbeiten | Quelltext bearbeiten]
Schreiben Sie einen Algorithmus in detailliertem Pseudocode auf, der die Balance für jeden Knoten eines AVL-Baumes ermittelt. Ihre Funktion soll als Argu- ment einen Knoten des Baumes akzeptieren und mit dem Wurzelknoten des Baumes aufgerufen werden.
Jeder Knoten x des Baumes hat folgende Attribute:
- x.key: Schlüssel von x
- x.left / x.right: Verweis auf linkes / rechtes Kind von x (null, wenn nicht vorhanden)
- x.parent: Verweis auf den Elternknoten von x (null, wenn Wurzel)
- x.height: Höhe des Teilbaumes mit Wurzelknoten x
- x.balance: die Balance des Knotens x
Nach Ausführung Ihres Pseudocodes soll das Attribut x.balance für jeden Knoten x des Baumes korrekt berechnet sein. Gehen Sie davon aus, dass Sie das Attribut x.height für jeden Knoten zuerst neu berechnen müssen, bevor Sie darauf in Ihrem Code (erstmalig) zugreifen.
Aufgabe 3.6[Bearbeiten | Quelltext bearbeiten]
Gegeben ist folgender AVL-Baum:
-%C3%9Cbungen_2019S_-_Task36.png)
(a) Fügen Sie zuerst den Schlüssel 1 und dann 11 in den oben gegebenen AVL-Baum ein. Falls notwendig, so rebalancieren Sie den Baum nach jedem Einfügen mit einer geeigneten Rotationsoperation (siehe Foliensatz Suchbäume), um wieder einen gültigen AVL-Baum zu erhalten. Markieren Sie dabei den unbalancierten Knoten mit maximaler Tiefe.
(b) Löschen Sie aus dem in Aufgabe 6 gegebenen AVL-Baum die Schlüssel 2 und 5 in dieser Reihenfolge. Falls notwendig, so rebalancieren Sie den Baum nach jedem Löschvorgang mit einer geeigneten Rotationsoperation (siehe Foliensatz Suchbäume), um wieder einen gültigen AVL-Baum zu erhalten. Markieren Sie dabei den unbalancierten Knoten mit maximaler Tiefe.
Aufgabe 3.7[Bearbeiten | Quelltext bearbeiten]
Lösen Sie folgenden Unteraufgaben zu B-Bäumen.
(a) Fügen Sie die Elemente der Folge
- 1, 3, 6, 8, 11, 14, 20, 40
in dieser Reihenfolge in einen anfangs leeren B-Baum der Ordnung 3 ein. Zeichnen Sie den B-Baum jeweils vor und nach jeder Reorganisationsmaßnahme und geben Sie den endgültigen B-Baum an.
(b) Geben Sie den B-Baum an, der durch Löschen der Schlüssel 11 und 8 (in dieser Reihenfolge) aus dem Baum von Unteraufgabe (a) entsteht. Stellen Sie den B-Baum nach jedem Zwischenschritt dar und führen Sie gegebenenfalls geeignete Reorgansi- sationsmaßnahmen durch.
Übung 4[Bearbeiten | Quelltext bearbeiten]
Aufgabe 4.1[Bearbeiten | Quelltext bearbeiten]
Die Wahrscheinlichkeit, dass es nach dem Einfügen von n gleichverteilt zufällig gezogenen Elementen in eine Hashtabelle der Größe m mit uniformer Hashfunktion zumindest eine Kollision gibt, ist näherungsweise:
(a) Wie groß muss m nach dieser Näherung gewählt werden, damit nach dem Einfügen von n = 23 Elementen mit 50% Wahrscheinlichkeit eine Kollision entsteht?
(b) Betrachte eine uniforme Hashfunktion h und eine Hashtabelle der Größe . Sei nun k ein Schlüssel und h(k) sein dazugehöriger Hashwert. Wie viele Schlüssel muss ein Angreifer nach der erwähnten Näherung durchprobieren, um mit 50% Wahrscheinlichkeit einen anderen Schlüssel mit gleichem Hashwert zu finden?
Aufgabe 4.2[Bearbeiten | Quelltext bearbeiten]
Gegeben seien folgende geordnete natürliche Zahlen:
- [19, 16, 11, 9, 20, 0, 3]
Fügen Sie diese in der vorgegebenen Ordnung jeweils in folgende Varianten von anfangs leeren Hashtabellen der Größe m = 9 ein und stellen Sie die einzelnen Schritte und die finale Belegung dar. Geben Sie weiters jeweils die durchschnittliche Laufzeit einer erfolgreichen Suche eines Elements an.
(a) Verkettung der Überläufer mit .
h(k) = k mod 9
h(19)=1, h(16)=7, h(11)=2, h(9)=0, h(20)=2, h(0)=0, h(3)=3
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| 9 0 |
19 | 11 20 |
3 | 16 |
durchschnittliche Laufzeit für erfolgreiche Suche:
Für das Sondieren (quadratisch und Double-Hashing) gilt .
(b) Quadratisches Sondieren mit
- und .
(c) Double-Hashing mit
h1 = k mod 9
h2 = (k mod 5) + 1
- h1(19)=1, h1(16)=7, h1(11)=2, h1(9)=0
- h1(20)=2 (Kollision) → 2+1=3
- h1(0)=0 (Kollision) → 0+1=1 (Kollision) → 0+2=2 (Kollision) → 0+3=3 (Kollision) → 0+4=4
- h1(3)=3 (Kollision) → 3+4=7 (Kollision) → (3+8)mod 9 = 2 (Kollision) → (3+12) mod 9 = 6
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| 9 | 19 | 11 | 20 | 0 | 3 | 16 |
durchschnittliche Laufzeit für erfolgreiche Suche:
Aufgabe 4.3[Bearbeiten | Quelltext bearbeiten]
(a) Die Funktion sort() der C++ Standard Library wird üblicherweise mit einer Kombination mehrerer Sortieralgorithmen namens Introsort implementiert. Finden Sie heraus, welche Algorithmen bei Introsort kombiniert werden. Erklären Sie kurz wie diese Kombination funktioniert und welche Vorteile sie bietet.
(b) Die Funktion stable sort() der C++ Standard Library muss laut Spezifikation stabil sein und eine Worst Case Laufzeit von n log(n) aufweisen (falls ausreichend zusätzlicher Speicher zur Verfügung steht). Mit welchem Sortieralgorithmus, den Sie aus der Vorlesung kennen, können Sie diese Spezifikation erfüllen?
(c) Sie finden den Sourcecode für die OpenJDK Implementierung der Datenstruktur HashMap unter: http://hg.openjdk.java.net/jdk8/jdk8/jdk/file/687fd7c7986d/src/share/classes/java/util/HashMap.java In dieser Implementierung wird die verkettete Liste der Überläufer für einen Hashwert in einen Suchbaum umgewandelt, falls sie zu lang wird. Finden Sie heraus, beiwelchen Operationen und unter welchen Bedingungen ein Suchbaum wieder zu einer verketteten Liste umgewandelt wird.
Aufgabe 4.4[Bearbeiten | Quelltext bearbeiten]
Sei P ein Ja/Nein-Problem für Instanzen mit Größe n. Nehmen Sie an, dass es eine Reduktion von P auf ein Problem Q gibt, die Zeit benötigt. Nehmen Sie weiterhin an, dass Problem Q NP-vollständig ist. Geben Sie für die folgenden Aussagen an, ob sie wahr oder falsch sind oder ob keine Aussage möglich ist. Begründen Sie Ihre Antwort.
(a) P ist in NP.
(b) P ist NP-schwer.
(c) P ist NP-vollständig.
Nehmen Sie nun zusätzlich an, dass Sie das Problem Q in Zeit O(m 2 log(m)) lösen können, wobei m die Eingabegröße einer Instanz von Q ist.
(d) Bedeutet dies, dass jede Instanz von P in polynomieller Zeit gelöst werden kann? Begründen Sie Ihre Antwort.
(e) Bedeutet dies, dass jede Instanz von Sat in polynomieller Zeit gelöst werden kann? Begründen Sie Ihre Antwort.
(f) Geben Sie eine obere Schranke für die Laufzeit (eines optimalen Algorithmus) für das Problem P an und begründen Sie Ihre Antwort kurz.
(g) Bedeutet dies, dass jede Instanz von Sat in O(n 8 ) gelöst werden kann? Begründen Sie Ihre Antwort.
Aufgabe 4.5[Bearbeiten | Quelltext bearbeiten]
Aufgabe 5. Im Folgenden sind verschiedene Probleme mit einem Zertifikat und einem Zertifizierer gegeben. Überlegen Sie sich, ob das Zertifikat und der Zertifizierer geeignet sind um zu zeigen, dass das gegebene Problem in NP ist. Begründen Sie Ihre Antwort.
(a)
- Problem: Gegeben sei ein Graph G. Ist G 3-färbbar?
- Zertifikat: Eine 3-Färbung von G.
- Zertifizierer: Überprüfe, ob keine zwei benachbarten Knoten die selbe Farbe haben.
(b)
- Problem: Ein Vertex Cover ist minimal, falls es kein Vertex Cover mit weniger Knoten gibt. Gegeben sei ein Graph G und ein Knoten v. Gibt es ein minimales Vertex Cover in dem v enthalten ist?
- Zertifikat: Ein minimales Vertex Cover C das v enthält.
- Zertifizierer: Überprüfe, ob C ein minimales Vertex Cover ist und ob v in C enthalten ist.
(c)
- Problem: Gegeben sei ein gewichteter Graph G, Knoten u und v sowie eine natürliche Zahl k. Gibt es einen Pfad von u nach v der Länge k oder kürzer?
- Zertifikat: Ein leerer String.
- Zertifizierer: Überprüfe mit Hilfe des Dijkstra Algorithmus, ob es einen Pfad von u nach v der Länge k oder kürzer gibt.
(d)
- Problem: Gegeben sei ein ganzzahliges Polynom p(x). Hat p keine Nullstellen?
- Zertifikat: Eine Nullstelle von p.
- Zertifizierer: Überprüfe, ob .
(e)
- Problem: Gegeben sei ein Graph G und eine Zahl k. Hat G einen Minimal Spanning Tree T, sodass es keinen Knoten in T gibt, dessen Grad größer als k ist?
- Zertifikat: Ein MSP T, sodass es keinen Knoten in T gibt, dessen Grad größer als k ist.
- Zertifizierer: Überprüfe, ob T ein Spanning Tree ist und es keinen Knoten in T gibt, dessen Grad größer als k ist. Berechne einen MST T' via Prim/Kruskal und überprüfe, ob das Gewicht von T' gleich dem Gewicht von T ist.
Aufgabe 4.6[Bearbeiten | Quelltext bearbeiten]
Das komplett vernetzter Subgraph Problem ist wie folgt definiert: Gegeben sei ein Graph G = (V, E) und eine natürliche Zahl k. Existiert ein komplett vernetzter Subgraph der Größe k in G, d.h., gibt es k Knoten in G, die alle paarweise adjazent sind?
Geben Sie eine polynomielle Reduktion von Independent Set auf komplett vernetzter Subgraph an und begründen Sie die Korrektheit der Reduktion.
Wenden Sie Ihre Reduktion auf die folgende Independent Set Instanz an: Kreis C 5 mit 5 Knoten {a, b, c, d, e} und k = 3.
Übung 5[Bearbeiten | Quelltext bearbeiten]
Aufgabe 5.1[Bearbeiten | Quelltext bearbeiten]
Betrachten Sie das im Allgemeinen NP-schwere Problem den größten komplett vernetzten Subgraphen in einem gegebenen Graphen zu finden, d.h. einen Teilgraphen mit maximal großer Teilmenge , sodass .
Entwerfen und beschreiben Sie einen polynomiellen Algorithmus in Pseudocode, der das Problem für den Spezialfall löst, dass G ein Intervallgraph ist. Gehen Sie dabei davon aus, dass die Eingabe eine Menge I von (nicht leeren) Intervallen ist und in I alle Intervallgrenzen paarweise verschieden sind. Die Ausgabe soll wiederum eine Teilmenge sein, die einem größten komplett vernetzten Subgraphen entspricht.
Begründen Sie die Korrektheit Ihres Algorithmus und geben Sie die asymptotische Laufzeit an.
Aufgabe 5.2[Bearbeiten | Quelltext bearbeiten]
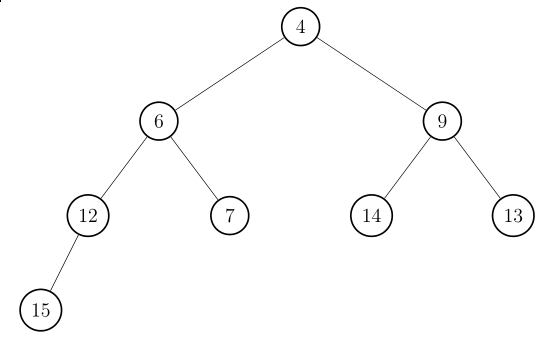
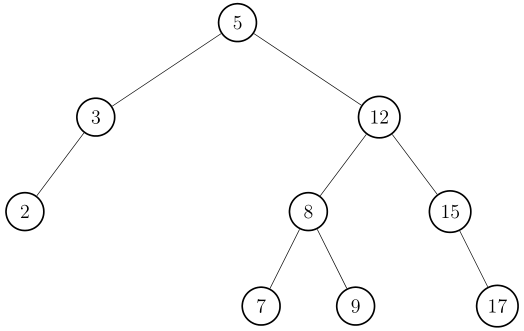
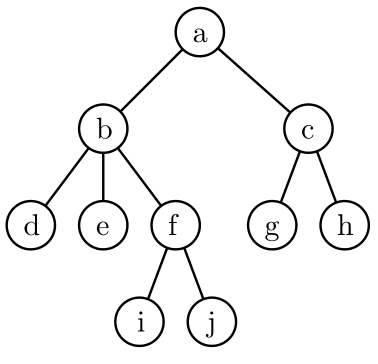
Führen Sie den Algorithmus zur Berechnung des Independent Sets mit maximalem Gewicht für den gegebenen Baum mit den Knotengewichten aus der Tabelle aus. Bestimmen Sie zu jedem Knoten u den Wert und den Wert . Geben Sie das berechnete gewichtete Independent Set und sein Knotengewicht an.
Handelt es sich bei der Lösung auch um ein maximales Independent Set (bezüglich Kardinalität)? Begründen Sie Ihre Antwort.
-%C3%9Cbungen_2019S_-_Task52.png)
Knoten a b c d e f g h i j Gewicht 6 4 9 2 3 6 1 1 5 4
-%C3%9Cbungen_2019S_-_Task52_solution.jpeg)
Independent Set = {c, d, e, i, j}
Nicht maximal bezüglich Kardinalität (es gibt 6 Blätter).Aufgabe 5.3[Bearbeiten | Quelltext bearbeiten]
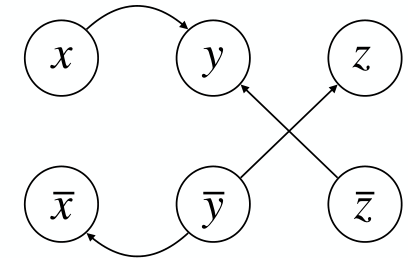
2-SAT bezeichnet eine Variante des Erfüllbarkeitsproblems aussagenlogischer Formeln (SAT), bei der jede Klausel der Eingabeformel genau zwei Literale enthält. Wir definieren nun folgenden Graphen:
Sei eine KNF-Formel mit genau zwei Literalen in jeder Klausel, die Menge der in F vorkommenden Variablen und . Der Implikationsgraph (implication graph) der Formel F ist der gerichtete Graph mit Knotenmenge und Kantenmenge .
Der Implikationsgraph zu sieht zum Beispiel so aus:
-%C3%9Cbungen_2019S_-_Task53.png)
Beantworten Sie die folgenden Fragen bzw. lösen Sie die folgenden Aufgaben:
(a) Geben Sie eine unerfüllbare 2-SAT-Instanz und den dazugehörigen Implikationsgraphen G an. Markieren Sie die starken Zusammenhangskomponenten von G. Was fällt Ihnen auf?
(b) Angenommen, eine starke Zusammenhangskomponente enthält die Literale l und l' 0, und τ ist eine erfüllende Belegung. Was kann man über die Wahrheitswerte τ(l) und τ(l') aussagen?
(c) Was bedeutet es, wenn eine starke Zusammenhangskomponente ein Literal und dessen Negation enthält?
(d) Angenommen, eine Menge L von Literalen ist eine starke Zusammenhangskomponente von G. Zeigen Sie, dass die Menge ebenfalls eine starke Zusammenhangskomponente von G ist.
Anmerkung. Angenommen, der Implikationsgraph G von F enthält keine starke Zusammenhangskomponente, die ein Literal und dessen Negation enthält. Sei G' der Graph, der durch Kontraktion der starken Zusammenhangskomponenten von G entsteht.1) Die folgende Prozedur konstruiert eine erfüllende Belegung τ von F:
Sei eine topologische Sortierung von . Wir betrachten die Komponenten der Reihe nach für (insbesondere hat keine eingehenden Kanten). Sei σ i : var (K i ) → {0, 1} die Belegung, die jedem Literal den Wert zuweist. Wir erweitern die Belegung τ um wenn die Variablen in K i noch nicht belegt sind.
- Gemeint ist der Graph mit und .
Aufgabe 5.4[Bearbeiten | Quelltext bearbeiten]
Wenden Sie den Branch-and-Bound Algorithmus zum Finden eines minimalen Vertex Covers auf den nachfolgenden Graphen an. Geben Sie den Ablauf des Algorithmus als Branch-and-Bound-Baum wieder. Geben Sie für jeden Schritt die obere Schranke U' und die untere Schranke L' an, sowie die aktuelle Teilinstanz und die aktuell beste gefundene Lösung S. (Falls mehrere Knoten für einen Branching-Schritt in Frage kommen, wählen Sie den mit der kleinsten Nummer.)
-%C3%9Cbungen_2019S_-_Task54.png)
Aufgabe 5.5[Bearbeiten | Quelltext bearbeiten]
Sei G = (V, E) ein ungerichteter Graph. Ein Matching (in G) ist eine Teilmenge M ⊆ E von Kanten, sodass keine zwei Kanten aus M einen Knoten teilen. Das Maximum Matching Problem besteht darin, ein Matching mit größtmöglicher Kardinalität zu bestimmen. Beweisen Sie, dass Maximum Matching in Polynomialzeit gelöst werden kann, wenn der Eingabegraph ein Baum ist.
Hinweis: Orientieren Sie sich an dem in der Vorlesung besprochenen Algorithmus für Independent Set auf Bäumen.
m <- leere Menge an Kanten
while T hat zumindest eine Kante
Sei e = (u,v) eine Kante, sodass v ein Blatt ist
Füge e zu m hinzu
Lösche aus T die Knoten u und v, sowie alle zu diesen beiden Knoten inzidenten Kanten
return m
Aufgabe 5.6[Bearbeiten | Quelltext bearbeiten]
Entwerfen und beschreiben Sie einen Branch-and-Bound-Algorithmus für das Optimierungsproblem Max 2Sat, welches wie folgt definiert ist:
- Gegeben sei eine Menge von Boole’schen Variablen sowie eine Menge von Klauseln mit genau zwei Literalen, d.h. für jede Klausel gilt und oder für und . Gesucht ist eine Wahrheitsbelegung der Variablen, die möglichst viele Klauseln erfüllt.
Beantworten Sie folgende Fragen:
(a) Wie repräsentieren Sie ein Teilproblem und wie erfolgt das Branching, d.h. das Aufteilen eines (Teil-)Problems in weitere Teilprobleme?
(b) Beschreiben Sie eine sinnvolle Möglichkeit für die Auswahl des nächsten Teilproblems. Nach welcher Strategie gehen Sie dabei vor?
(c) Geben Sie Heuristiken für die Berechnung einer unteren und oberen Schranke an.
Übung 6[Bearbeiten | Quelltext bearbeiten]
Aufgabe 6.1[Bearbeiten | Quelltext bearbeiten]
Betrachten Sie das Knotenfärbungsproblem OptColor für die wie folgt definierte Familie von Graphen . Der Graph für hat die Knotenmenge und die Kantenmenge . Entwerfen Sie einen Algorithmus zur optimalen Färbung aller Graphen G i und geben Sie den zugehörigen Pseudocode an. Gehen Sie davon aus, dass der Pseudocode , und x zu dem Graphen als Übergabeparameter bekommt. Begründen Sie die Korrektheit und Optimalität der Färbung. Welche Beobachtungen können Sie über die optimalen Färbungen der Graphen machen?
Aufgabe 6.2[Bearbeiten | Quelltext bearbeiten]
Das 4-Color Problem ist wie folgt definiert: Gegeben sei ein ungerichteter Graph G. Kann man die Knoten des Graphen mit den vier Farben A, B, C und D so einfärben, dass benachbarte Knoten nicht die gleiche Farbe besitzen?
Beweisen Sie, dass 4-Color NP-vollständig ist.
Hinweis: Sie können eine einfache Reduktion erstellen, indem Sie Ihr Wissen aus der Vorlesung nutzen, dass 3-Color NP-vollständig ist. Um zu beweisen, dass 4-Color in NP liegt, benutzen Sie die Definition von NP.
Aufgabe 6.3[Bearbeiten | Quelltext bearbeiten]
Seien A, B, C, D Ja/Nein-Probleme in NP und n die Eingabegröße. Angenommen, es gibt
- eine Reduktion von A auf B mit Laufzeit O(n 2.5 ),
- eine Reduktion von B auf C mit Laufzeit O(n · log(n)),
- sowie eine Reduktion von C auf D mit Laufzeit O(n 4 ).
Beantworten Sie die folgenden Fragen:
- Geben Sie die engste obere Schranke für die Laufzeit einer Reduktion von A auf D in O-Notation an, die sich aus diesen Annahmen ableiten lässt und begründen Sie die Antwort.
- Nehmen Sie an, dass C NP-schwer ist. Was folgt daraus für die Komplexität der Probleme A, B, D?
- Nehmen Sie an, D kann in Polynomialzeit gelöst werden. Was folgt daraus für die Komplexität der übrigen Probleme A, B, C?
Aufgabe 6.4[Bearbeiten | Quelltext bearbeiten]
Lösen Sie die folgende Instanz des Gewichteten Interval Scheduling Pro- blems mittels Dynamischer Programmierung. Geben Sie das Array M an, sowie jeweils die Werte und M [j − 1]. Geben Sie außerdem für jeden Job j den Wert p(j) an. Berechnen Sie anschließend aus diesem Array eine Lösung und erklären Sie wie Sie zu dieser Lösung gekommen sind.
| Job | Start | Ende | Gewicht |
|---|---|---|---|
| 1 | 10 | 18 | 11 |
| 2 | 3 | 25 | 7 |
| 3 | 14 | 16 | 1 |
| 4 | 1 | 4 | 2 |
| 5 | 3 | 10 | 5 |
| 6 | 12 | 15 | 3 |
| 7 | 4 | 6 | 1 |
| 8 | 4 | 7 | 2 |
| 9 | 19 | 24 | 9 |
| 10 | 15 | 21 | 10 |
| 11 | 6 | 12 | 1 |
Aufgabe 6.5[Bearbeiten | Quelltext bearbeiten]
Betrachten Sie folgenden rekursiven Algorithmus zur Berechnung des n-ten Elements einer Zahlenfolge.
Sequence(int n):
if n <= 4
return 1
else
return Sequence(n-Sequence(n - 1)) + Sequence(n-Sequence(n - 4))
Geben Sie die ersten 10 Elemente der Zahlenfolge an. Wandeln Sie dann den Algorithmus um in einen Algorithmus mittels Dynamischer Programmierung und analysieren Sie dessen Laufzeit. Was ist der größte Vorteil Ihres Dynamischen Programms gegenüber dem ursprünglichen Algorithmus?
Sequence(n):
erstelle S[] der Länge n
for i = 1 bis 4
S[i] = 1
for i = 5 bis n
S[i]= S[i - S[i-1]] + S[i - S[i-4]]
return S[n]
Die Laufzeit liegt in O(n). Berechnete Zwischenergebnisse werden abgespeichert und müssen somit nicht neu berechnet werden.
Aufgabe 6.6[Bearbeiten | Quelltext bearbeiten]
Gegeben sei eine Folge von n natürlichen Zahlen. Ihre Aufgabe ist es, die Länge der längsten strikt aufsteigenden Teilfolge in (a i ) zu bestimmen, in der keine zwei geraden Zahlen aufeinanderfolgen dürfen. Entwerfen und beschreiben Sie einen Algorithmus mittels Dynamischer Programmierung um dieses Problem zu lösen. Die Laufzeit soll nicht überschreiten.
Beispiel: Sei . Die Folge (1, 4, 5, 7, 8) als Teilfolge von wäre zulässig, da die Folge strikt aufsteigend ist und keine zwei aufeinanderfolgenden Zahlen gerade sind. Die Folge (1, 4, 6, 7, 8) ist nicht zulässig, da sie zwei aufeinanderfolgende Zahlen enthält, die gerade sind. Die längste Teilfolge von (a i ), die strikt aufsteigend ist und keine zwei aufeinanderfolgenden Zahlen enthält, die gerade sind, ist in diesem Beispiel (1, 4, 5, 6, 7, 8).
Func(seq[]):
in = neues Array der Länge seq.length
max = 0
for i = 0 bis seq.length - 1
for j = 0 bis i - 1
if seq[j] < seq[i] und !(seq[i]%2==0 && seq[j]%2==0) und in[j] > in[i]
in[i] = in[j]
in[i] = in[i] + 1
max = max(in[i], max)
return max
Übung 7[Bearbeiten | Quelltext bearbeiten]
Aufgabe 7.1[Bearbeiten | Quelltext bearbeiten]
Betrachten Sie die folgende Instanz des symmetrischen Traveling Salesman Problems:
-%C3%9Cbungen_2019S_-_Task71.png)
Wenden Sie die Spanning-Tree-Heuristik aus der Vorlesung auf diese Instanz an und illustrieren Sie klar jeden Ihrer Schritte. Konstruieren Sie dabei Ihre Eulertour von A ausgehend und besuchen Sie die möglichen Knoten in alphabetischer Reihenfolge, wenn diese nicht eindeutig ist. Welche Länge hat Ihre Tour P ? Ist hier die Gütegarantie 2 aus der Vorlesung eingehalten?
Aufgabe 7.2[Bearbeiten | Quelltext bearbeiten]
Gegeben ist eine Instanz I = (G, k) von Independent Set mit dem unten abgebildeten Eingabegraph G. Wenden Sie der Reihe nach die in der Vorlesung besprochenen Problemreduktionen von Independent Set auf Vertex Cover sowie von Vertex Cover auf Set Cover an, um aus der Instanz I eine äquivalente Instanz I' = (S', k') von Set Cover zu erzeugen.
-%C3%9Cbungen_2019S_-_Task72.png)
Aufgabe 7.3[Bearbeiten | Quelltext bearbeiten]
Eine einfache Heuristik für das Traveling Salesman Problem (TSP) ist die Nearest Neighbor Heuristik. Sie startet bei einem beliebigen Knoten und gehen dann immer zu einem noch nicht besuchten nächstliegenden Knoten weiter. Sind alle Knoten erreicht, wird der Pfad zu einer Rundtour geschlossen.
Zeigen Sie mit einem möglichst einfachen Beispiel, dass diese Heuristik auch für das Euklidische TSP nicht immer eine optimale Lösung liefert.
Weiters: Beweisen oder widerlegen Sie, dass diese Heuristik für das Euklidische TSP die Gütegarantie 3/2 besitzt.
Aufgabe 7.4[Bearbeiten | Quelltext bearbeiten]
Gegeben ist eine Variante des Rucksack-Problems, bei der jeder Gegenstand beliebig oft gewählt werden kann. Zeigen Sie, dass der Greedy-Algorithmus aus der Vorlesung für dieses Problem eine Gütegarantie von 1/2 erzielt.
Aufgabe 7.5[Bearbeiten | Quelltext bearbeiten]
Sei G = (V, E) ein gerichteter Graph. Jeder Kante (u, v) ∈ E ist ein Symbol σ(u, v) aus einem endlichen Alphabet Σ zugeordnet (es kann auch mehrere ausgehende Kanten mit dem gleichen Symbol geben), sodass jede Kantenfolge ein Wort aus Σ ∗ erzeugt. Umgekehrt muss ein Wort nicht unbedingt einer Kantenfolge in G entsprechen.
(a) Geben Sie einen Polynomialzeitalgorithmus an, der für einen Eingabegraphen G, einen Startknoten v 0 , und ein Wort s entscheidet, ob eine von v 0 ausgehende Kan- tenfolge in G existiert, die das Wort s erzeugt, und gegebenenfalls eine entspechende Kantenfolge zurückliefert.
Angenommen, jeder Kante (u, v) ∈ G ist eine Wahrscheinlichkeit p(u, v) > 0 zugeordnet, mit der die Kante ausgehend von u gewählt wird. Für jeden Knoten u ergibt die Summe der Wahrscheinlichkeiten der von u ausgehenden Kanten 1. Sei eine von Knoten v ausgehende Kantenfolge. Das Produkt entspricht der Wahrscheinlichkeit, dass ein von v ausgehender "Random Walk", bei dem an jedem Knoten u zufällig eine ausgehende Kante (u, w) mit Wahrscheinlichkeit p(u, w) gewählt wird, die Kantenfolge π wählt.
(b) Erweitern Sie Ihren Algorithmus aus Unteraufgabe (a), sodass er eine wahrschein- lichste von v 0 ausgehende Kantenfolge zurückliefert, die das Wort s erzeugt. Welche (asymptotische) Laufzeit hat Ihr Algorithmus, in Abhängigkeit von |V |, |E| und |s|?
Aufgabe 7.6[Bearbeiten | Quelltext bearbeiten]
Gegeben ist das folgende Planungsproblem. Ein Roboter bewegt sich auf einem Raster mit Feldern. Zu jedem Zeitpunkt kann er an seinem aktuellen Standort eine der vier Richtungen wählen. Er bewegt sich daraufhin auf das in dieser Richtung gelegene benachbarte Feld und erhält einen dem Feld zugeordneten Wert als Belohnung , es sei denn, er würde das Raster dadurch verlassen—in diesem Fall bewegt er sich nicht von der Stelle und erhält eine "Belohnung" von .
Eine Strategie ist eine Funktion
- ,
die für jeden Standort und Zeitpunkt die Bewegungsrichtung des Roboters angibt. Für jeden Startpunkt S 0 ∈ S und jede Strategie π ergibt sich eine Episode
- .
Der Nutzen G t für einen Zeitpunkt t ist die P Summe aller Belohungen, die der Roboter bis zum Ende der Episode erhält, also . Eine optimale Strategie ist eine Strategie , die für jeden Standort ab dem Zeitpunkt t den maximalen Nutzen liefert. Der Wert eines Punktes zum Zeitpunkt entspricht dem von einer optimalen Strategie erzielten Nutzen G t bei Startpunkt .
Geben Sie einen Polynomialzeitalgorithmus an, der die Dimension n des Rasters, die Länge T einer Episode, sowie die Funktion (als Tabelle) als Eingaben erhält, und für jeden Punkt S ∈ S mittels dynamischer Programmierung den Wert berechnet. Nutzen Sie dazu Bellmans Gleichungen.
Wenden Sie Ihren Algorithmus auf die unten dargestellte Instanz mit n = 4 und T = 3 an (der Wert ist in Abbildung 1 im jeweiligen Feld eingetragen). Stellen Sie die von einer optimalen Strategie vorgeschlagenen Bewegungsrichtungen für t = 0 dar, indem Sie Abbildung 2 vervollständigen.
| 0 | 0 | 0 | 8 |
| 0 | 0 | 0 | 0 |
| 0 | 10 | 0 | 0 |
| 0 | 5 | 0 | 0 |
| ← | |||
Materialien
Neues Material hinzufügenT
- Task21.png (details)
- Task22 solution.png (details)
- Task22.png (details)
- Task27.png (details)
- Task31.png (details)
- Task34 solution.jpg (details)
- Task36.png (details)
- Task52 solution.jpeg (details)
- Task52.png (details)
- Task53.png (details)
- Task54.png (details)
- Task71.png (details)
- Task72.png (details)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}